
Quick iterations are essential to test concepts, discard bad ideas and get focused on what may actually solve our problem.
When I first started using Python, I used scripts for everything. Scripts are awesome to automate stuff and can be easily integrated into bigger programs. They work, but are they perfect?
The definitely introduce some problems, which keeps them apart from that category. Some of them are:
- When you are quickly changing the code, you may need to refactor a lot of things. A disorganized script will have a lot of commentaries around and as soon as you stop working on it, you will forget most of what you were trying to do, making it harder to just “come back and finish”.
- The results are shown (probably) in the shell or in another window you set up for that (in the case of graphs). This action of jumping around can hurt your focus, and the lost time piles incrementally.
- If you organize your script, you may be able to focus on certain pieces that you want to improve. However, you may not want to run the whole script every time. Most of the time you want to improve some pieces, but you have to run everything over and over because you need the previous steps. There are ways to circumvent this, but in general, it is just annoying.
What would you think if I said that there is some tool that can allow you to keep trying out things fast, without sacrificing the benefits of the scripts? That there is a solid, well-known method that people are using everywhere?Meet Jupyter.
There are several ways to install jupyter and get started with the tool. In this case we will assume that you can just install it via pip, but that may not be the easiest way and can have some requirements before you can work with it:
pip install jupyterJupyter has the concept of “notebooks”. Those are files that can be seen as “jupyter scripts”. To view, edit and execute them, you will need jupyter.
To get started, let’s just run the
jupyter notebook
You can create your notebooks in this interface. It is as easy as clicking “New” and selecting “Python”. Jupyter can create notebooks in other languages, but we will go into that in another occasion.

You have a “Cell”. Notebooks are made of cells, and you can run any python code you want in every cell. You can have, in fact, everything in a single cell, but that’s not something you’d want. It is a better practice to have everything as
For example, if you are importing data from the internet (slow process) and want to process that data after it is ready, put those actions into separate cells. Then, execute them separately.
With this approach, you will be able to focus on the “processing” step without wasting time importing the same data over and over.
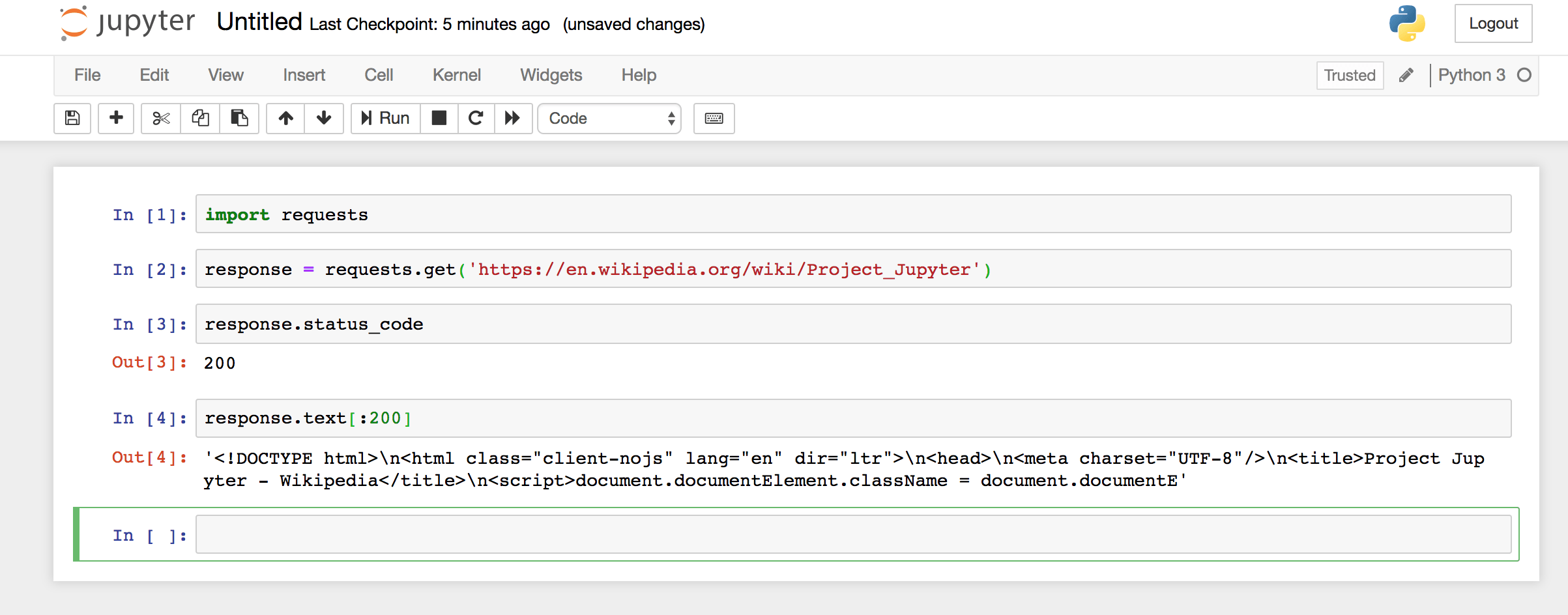
Once you are done implementing whatever you were working on, you can just go to File > Download as > Python, and you will have a script that just works. It may require some refactoring to improve its reusability and readability, but it is just a matter of form, not of functionality.
A big advantage of
This is so widely adopted, that if you upload a notebook file to
Give it a try, you definitely won’t regret it!